Observations and Conclusions
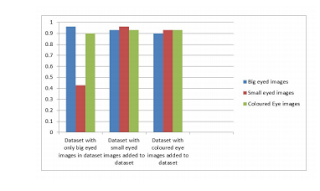
Observations Graphical Illustration of the differences in accuracy with additions to dataset The below figure shows the ratio of number of correctly classified images to total number of images for a test set of 30 images. This is displayed in the form of a column chart for different training data sets. On adding new coloured eye images, the accuracy of the model actually drops. This is because the classifier gets confused with more of a variety of pictures. There’s more of a conflict between images in the open set and images in the closed set. This reduces the accuracy. The algorithm to detect the lip based on colour fails as there isn’t much of a gradient colour difference. The classification of yawn using SVM classifier isn’t very accurate. With respect to the blink model, the model would perform better if the mouth area was already localised and the classifier worked on the cropped image. This wou...


